Introduction
Overview
Teaching: 10 min
Exercises: 5 minQuestions
Why would I want to advance my skills?
Objectives
Be able to help yourselves and others.
Once you have a job running on HPC it might be tempting to stop learning further about HPC. This might be due to resource constraints, lifespan of project, or a global pandemic. The goal of a researcher when using HPC resource may be to get the results, understand them and publish. The researcher has not seen the possibility of using the HPC resource in an efficient way that could speed up turnaround of jobs, perform quicker analysis, or fix any problems quickly that may appear.
A researcher that can spend more time learning about HPC can perform more effectively and may see new ways to approach a problem.
What problems have you already experienced?
Think about any problems you experienced, did you solve them yourself? If not, did you spend time searching for help? Could you have performed your work in a different (more efficient) way? How long did your jobs run on the system? How did you estimate the resources required?
Development practice on HPC
Navigating command line and editor.
Learning to use tools correctly and effortless allows more time spend on the actual work. Learning to drive requires commitment and time to make the car seem to be an extension of the body. HPC is no different, learning to use development tools to write SLURM jobs, develop code, and managing change should be an extension of your mind without having to think about it.
HPC is a bit different to development on your desktop. HPC tends to be run across an ssh connection so graphical windows can be unnatural to the experience. Software tend to be built specially for the system rather than using generic packages from distributions that are find for a few hours use on a desktop but using it for 1000s of hours on a HPC system requires optimisation to make use of the resource.
Due to the importance of the results coming from HPC (you do NOT want to rerun a jobs that can take a long time or cost money) revision control is important. No more:
cp my_job.sh my_job_050720.sh
# edit my_job.sh
sbatch my_job.sh
# gives my_job.sh to colleague that finds error>
And instead use Git
git clone https://github.com/ARCCA/my_job
# edit my_job.sh
sbatch my_job.sh
git add my_job.sh
git commit -m "Modified command line argument to random.exe"
git push origin
# share repository with colleague who can see changes.
Experiment with software
As a user on HPC you are free to build software and experiment with build options or dependencies of the software. Doing this yourself you learn about the different options available when building software and may find more effective set of options. This speeds up your workflow rather than waiting for others to build the software.
Debugging and optimisation
When you experience a problem with running a job on a HPC system or run the job in parallel to gather more results the best person to solve this is the person who understands what is being achieved. By giving you tools to try and find out why the job does not work will allow the user to see and understand their job in more detail and how it impacts their work. Of course, support is always available where issues can be fixed but gaining the tools and knowledge should make the user feel confident about the jobs they are running. GPUs, filesystems, number of processors/cores to use are all important factors to understand their uses.
What are GPUs?
Part of this workshop will look at GPUs, but what are they? Can they be easily be used or are they specialist hardware? Find out whether the software you want to run on HPC can use GPUs, it usually leads to a faster way to run your job. Machine learning is the current trend to use GPUs extensively due to its natural fit to be used with GPUs.
General knowledge of the job scheduler
Job schedulers have 1 job and that is to find the resource you request and run your job. Job schedulers can also provide you with different ways to run your job, maybe you need interactive session, or you need to run your job thousands of times at the same time. A job scheduler also records lots of information about your jobs and this can be queried to find out more about a particular run.
Finally, when using the job scheduler SLURM do not underestimate the power of
$ man sbatch
The man pages provide a wealth of information.
Key Points
Advanced skills allow you to help yourself more.
Development tools for building code
Overview
Teaching: 30 min
Exercises: 15 minQuestions
What more can I do with the command-line?
How can I revert changes to code?
How can I build things in a certain order?
What options are they when I compiler code?
Objectives
Move around the command-line with ease.
Understand options available to revision control.
Use simple makefiles to build code.
Understand some basic compiler options.
Command-line and tools at your fingertips.
A Linux course is a good start to learn the required skills needed to access HPC systems hosted across a network via ssh. The command-line is a very powerful device, once mastered, desktops can seem inefficient when performing some tasks.
Editing a long command.
You may have just written a very long command-line - maybe with a few pipes (
|) or pasted in a long line of text (a search term). You discover you spelt part of the command incorrect, how do you get to that part of the line?
The default shell on many Linux systems is Bash. Bash provides the commands and features for the user to interact with
the system. Bash provides a number of options, these can be seen with set -o
One particular useful feature to know about if the editing mode of Bash. These are descrived as emacs or vi mode.
These are the 2 most famous editors on Linux - a regular Linux user usually finds themselves either using emacs or
vi eventually. These editors have different ways to navigate within text. Foe example in emacs, CTRL-a will
position the cursor at the beginning of the line, CTRL-e to the end. In vi , ^ will position the cursor at
beginning of the line, $ to the end.
Finding currently used options
Find the current set of options used by your Bash shell and find the editing mode used.
Solution
Printing the current settings can be achieved simply with:
$ set -oThat produces:
<...> emacs on <...> vi off <...>
The options can be changed by giving the preffered way of navigating
$ set -o vi
What other options?
There are many options that can be set, such as changing behaviour what a command fails in a pipe. See
man bashfor explanation of options.
Terminal managers
One aspect of using a remote shell via SSH is that if you logout you kill any processes that were running. Utilities
such as nohup can be used to stop processes being stopped such as long-running download of a data file. Alternatively
a terminal manager that remains open on the remote side until you decide to close it can be used instead.
There are 2 main terminal managers in Screen and Tmux.
Screen is a GNU project that has been around for a long time. You can create new sessions or attach to existing sessions remotely. For example on your desktop or laptop the following alias to ssh to the remote machine can be used:
$ alias sshhawk1='ssh -t hawk1 screen -RR'
Where hawk1 is a ssh host defined in ~/.ssh/config
Host hawk1
Hostname hawklogin01.cf.ac.uk
User c.username
ForwardX11 yes
ForwardX11Trusted yes
The alias will allow just sshhawk1 to be typed and it will either connect to any detached screen session or create a
new session. On the remote server (note the ssh config fixes the login node to hawklogin01) screen -ls can list the
sessions running.
Tmux is available as a module on Hawk with module load tmux. See documentation or man tmux.
Revision control
One of the hardest things to get into a habit with is revision control. There is a long history of revision control software. Personally started wth RCS, used Subversion in a previous job but not the uniquitous revision control software is Git. Git tends to be installed on many Linux systems and is available on Windows via Git for Windows and on Mac via “Xcode Command Line Tools”.
Git can be used locally or distributively but the main thing to grasp that with Git there is no “central” version of the code. Git repositories can be copied and maintained independently of each other. The only thing that places some control to Git is to work to an agreed workflow. Github is a popular site to host Git repositories. Cardiff University hosts its own Gitlab repository. These sites allow for repositories to be forked (or copied to another user) and then by agreement within the project the changes can be fed back to the original repository. When changes are performed usually branches (or a specific copy of the code for the one change) which can then be merged back to either a fork or the original repository.
A list of common man pages for Git commands are:
$ man git-init
$ man git-clone
$ man git-branch
$ man git-push
$ man git-pull
$ man git-log
Clone a repository
Clone this documentation site from Github at https://github.com/ARCCA/hpc-advanced.git
Solution
$ git clone https://github.com/ARCCA/hpc-advanced.git
Many of the operations in Git can be performed directly on the website of the Git repository. This can be useful for simple changes.
Further Git information
Look out for courses and read online tutorials (Github has a good starter guide). Find excuses to use it and practice and get collaborating with colleagues by pushing job scripts online.
Dependency in tasks
There are many tools available to solve dependencies. A traditional (and tried and tested) method is the Makefile
method.
Makefiles are simple text files that describe a dependency between files or operations. These are usually used to describe dependencies for building code but can be used for many tasks such as copying files from the Internet before running your job on the login node.
What dependencies do you have in your work?
Think about the dependencies you may have in your work. Could things be performed in parallel or serial?
A Makefile is a file containing variables and dependency information (usually on files). For example a simple “Hello
world” example might be:
CC=gcc
hello: hello.o
$(CC) $^ -o $@
hello.o: hello.c
$(CC) $^ -c -o $@
This makefile will build the hello executable by depending on hello.o that has a rule to be created using hello.c.
See Make for further information.
Compiling code
Compiling code on HPC can be tricky due to the performance of the code can be positively or negatively impacted with compiler options. For example recent Intel processors have a new instruction set AVX512. If the code is not designed to benefit from this it can actually be negatively impacted.
For completely new code it could be worth using default compiler options of -O2 to begin with. Both Intel and GNU
Compilers have this option.
To load the default version of the Intel Compiler use:
$ module load compiler/intel
To load the default version of the GNU compiler use:
$ module load compiler/gnu
Find out the available options
How could the available options to compilers be found?
Solution
Using the
manpages is a good start.$ man icc $ man gcc
Intel compilers have a few features worth highlighting:
- the aggressive default optimisation that can change results of calculations. This is
controlled with
-fp-modeloption.-fp-model precisecan help with numerical stability or to reproduce answers. - the dependency on the underlying GNU compiler for C++ compatability means for later versions of the C++ standard a
GNU compiler that supports that standard is also loaded. e.g.
$ module load compiler/gnu/8 $ module load compiler/intel
There is also the PGI compiler, loaded with module load compiler/pgi. For all available compiler versions see module av
compiler.
Key Points
Navigating the command-line quickly can save time and reduce mistakes.
Revision control is not just good practice but good science.
Repeating multiple steps can be quick.
Compilers are not smart, requires smart users to tell them what to do.
Installing packages
Overview
Teaching: 15 min
Exercises: 30 minQuestions
How do I install a package for framwork/language X?
Can I use the operating system package manager?
Objectives
Install packages for a wide range of languages such as Python, R, Anaconda, Perl
Use containers to install complete software packages with dependencies in a single image with Singularity.
Installing packages for common frameworks/languages is very useful for a user on HPC to perform. Fortunately we allow downloads from the Internet so this is quite easy to achieve (some HPC systems can be isolated from the Internet that makes things harder). There will be many ways to install packages for programs, for example Perl can be just the operating system version of Perl or part of a bigger packages such as ActiveState Perl. ActiveState has its own package system rather than using the default package system in Perl. However we aim to provide the user in this section to be able to understand how packages work and install for common languages.
Once installed on the login node, the SLURM job scripts can be written to take advantage of the new package or software. You do not need to install the package again!
Check versions
Versions of software modules can be checked with
module av, for example for Python$ module av pythonSpecifying the version of the software also makes sure changes to default version will not impact your jobs. For example default python loaded with
module load pythoncould install packages into one location but if the default version changed it will not automatically reinstall those packages.
Python
Python is becoming the de-facto language across many disciplines. It is easy to read, write and run. Python 3 should be preferred over the now retired Python 2. On Hawk a user can load Python from a module
$ module load python/3.7.0
Python versions
Calling Python can be performed using just
pythonor with the version number such aspython3or even more exactpython3.7. To be sure you are calling Python 3 we recommend running withpython3rather than the unversionedpython. What is the difference on Hawk?Solution
$ python --versionwill print
Python 2.7.5
Python 3.7.0 is now loaded into your environment, this can be checked with
$ python3 --version
$ Python 3.7.0
Installing a package
To install a package we recommend using the pip functionality. This provides many packages of Python and handles
dependencies between the packages. For a user on Hawk, this can be run as
$ pip3 install --user <package>
Pip versions
Pip (just like Python) also is versioned with
pipjust being some OS default. Whilstpip3will call the Python 3 version of Pip. This is important to match overwise it will install packages in the wrong location. What versions are available on Hawk?Solution
There is no default OS
pipbutpipandpipare supplied by the module.$ pip --version $ pip3 --versionBoth print
pip 20.0.2 from /apps/languages/python/3.7.0/el7/AVX512/intel-2018/lib/python3.7/site-packages/pip (python 3.7)
Where <package> is the name of the package. The packages can be found using the Python Package Index or
PyPI.
The main concept for the user is to use --user that places the package in $HOME in this case in $HOME/.local/lib/python3.7/site-packages. This is automatically in the searchpath for Python when importing the module.
Example
To install a rather unhelpful hello-world package, run
$ pip3 install --user pip-hello-world
This will install the package in your $HOME directory.
This package can be tested with the following Python script
from helloworld import hello
c = hello.Hello()
c.say_hello()
The script will produce
'Hello, World!'
Virtual environments
Python supports a concept called virtual environments. These are self-contained Python environments that allows you to install packages without impacting other environments you may have. For example:
$ python3.7 -m venv pyenv-test $ source pyenv-test/bin/activate $ pip3 install pip-hello-world $ python3.7 $ deactivateEverything is contained with the directory
pyenv-test. There was also no need to specify--user. For beginners this can be quite confusing but is very useful to master. Once finished you candeactivatethe environment`.
R
R is a language for statisticians. It is very popular language to perform statistics (its primary role). Package
management for R is inbuilt rather than using a separate program to perform it.
On Hawk, R can be loaded via the module system with
$ module load R/3.5.1
Example
Running R, the following command will install the jsonlite package
install.packages(“jsonlite”)
# (If prompted, answer Yes to install locally)
# Select a download mirror in UK if possible.
Where jsonlite is the package name you want to install. Information can be found at
CRAN
In this case the package will be installed at $HOME/R/x86_64-pc-linux-gnu-library/3.5/
Anaconda
Anaconda is a fully featured software management tool that provides many packages for many different languages. Anaconda allow dependencies between software packages to be installed.
Since Anaconda keeps updating we can load the module on Hawk with
$ module load anaconda
This should load a default version of Anaconda. Specific versions can be loaded as well.
Example
A package can then be installed with
$ conda search biopython
$ conda create --name snowflakes biopython
This first checks there is a biopython package and then creates an environment snowflakes to store the package in.
The files are stored in $HOME/.conda
This package can then be activated using
$ conda info --envs
$ . /apps/languages/anaconda3/etc/profile.d/conda.sh
$ conda activate snowflakes
$ python
$ source deactivate
This first lists all environments you have installed. Then activates the environment you would like and then you can
run python. Finally you can deactivate the environment.
Newer versions of Anaconda may change the procedure.
Anaconda directory
Every package you download is stored in
$HOME/.condaand also lots of other files are created for every package. Overtime this directory can have many files and will reach the quota limit for files. We recommend usingconda clean -ato tidyup the directory and reduce the number of files.
Perl
Perl has been around for a long-time but becoming uncommon to see being used on HPC. On Hawk we recommend using the operating system Perl command so no module is required.
$ perl --version
To manage packages we can use the cpanm utility. This can be installed in your home directory with
$ mkdir -p ~/bin && cd ~/bin
$ curl -L https://cpanmin.us/ -o cpanm
$ chmod +x cpanm
Then setup cpanm with
$ cpanm --local-lib=~/perl5 local::lib
$ eval $(perl -I ~/perl5/lib/perl5/ -Mlocal::lib)
$ perl -I ~/perl5/lib/perl5/ -Mlocal::lib
# Add output from perl command above to $HOME/.myenv
This will install Perl packages in $HOME/perl5.
Example
Install the Test::More package.
$ cpanm Test::More
Then run the following Perl script
use Test::More;
print $Test::More::VERSION ."\n";
Which should produce something like
1.302175
Singularity
Singularity is a container solution for HPC where alternatives such as Docker are not suitable. Singularity can pretend to be another operating system but inherits all the local privilege you have on the host system. On Hawk we do not want anyone to be able to run software as another user - especially root. Also containers are immutable so you save files inside containers - $HOME and /scratch are mounted within the image.
Singulairity is available as a module with:
$ module load singularity
The latest version should be preferred due to containing the latest versions of the code that may include security and performance fixes.
Singularity can then be used, initially users will want to download existing containers but eventually you can build you own - maybe via the Singularity Hub
MPI and GPUs
Singularity supports using MPI and GPUs. MPI can be tricky especially with OpenMPI but GPUs are supported using the
--nvcommand line option that loads the relevent GPU libraries into the container from the host operating system.
Example
To download a container from Singularity Hub then you can run:
$ singularity pull shub://vsoch/hello-world
This will pull down an image file hello-world_latest.sif. This can be run with:
$ singularity run hello-world_latest.sif
This produces the following output:
RaawwWWWWWRRRR!! Avocado!
Docker Hub can also be used for Docker containers such as
$ singularity pull docker://ubuntu
You can then run a Ubuntu application on Redhat, e.g.
$ singularity exec ubuntu_latest.sif cat /etc/os-release
A useful site for GPUs is NGC that hosts containers for software optimised for GPUs. Instructions are on the website.
Containers
Containers allows a user to build once and run anywhere (if same processor type). A recipe file can be created to store the exact steps used to create the image. This can make sure any code is reproducible by others. It is useful for packages that assume a user has root access to their machine and install OS level packages for dependencies.
Others?
There may be other software package managers that you want to investigte. Please get in touch with us if you need help.
For example, the Spack is a software manager to make it easy to install packages. Finally there is
also the traditional autoconf and make approach. For example you can build software with:
$ ./configure --prefix=$HOME/my_package
$ make
$ make install
This will install my_package in your $HOME directory.
Experimenting with software packages is encouraged to find new and novel ways to perform your research.
Key Points
Users can control their own software when needed for development.
Debugging
Overview
Teaching: 30 min
Exercises: 15 minQuestions
What do I do to find out why my code failed?
Are debuggers just for compiled languages?
Why are debuggers hard to use?
Objectives
Use a variety of options from compiler options to full blown commerical debuggers to discover an issue with the code.
Understand how Python can be debugged with Pdb.
Use the correct tool to debug the relevent issue.
Bugs! Software is very hard to write without them so skills to squash them is required. For compiled languages, e.g. C/C++/Fortran there is much that can be done at compile-time to highlight issues, as well as at runtime. For other languages, e.g. Python, issues are only highlighted at runtime. For HPC, highlighting issues at runtime can mean wasted resources.
Bugs
Some examples of bugs are:
- Unexpected error (Segmentation fault, crashes)
- Different results (even crashes) on different systems or number of processors.
- Change does more than it was supposed to do.
Print statements can be useful but can take time, and adding code can change behaviour of the program and the bug can change or disappear.
Compiled languages
Most compilers have methods to detect issues at compile-time. These are usually recommendations due to non-compliance of standard or type conversion. There is also options enabled at compile time to help debugging at runtime.
GNU/GCC
GNU compilers have a number of options. Using gfortran as an example (gcc and g++ share options).
To turn on debug symbols, adds line number of source file information:
$ gfortran -g main.f90
To turn traceback to highlight where the program crashed. Provides line number of source file.
$ gfortran -fbacktrace main.f90
To force a strict standard compliance reduces issues due to compiler specific options being used that harms portability.
$ gfortran -std=f95 main.f90
To strictly look for issues in code
$ gfortran -std=f95 -pedantic -Wall main.f90
Intel
Intel Compilers have similar options to GNU. Using ifort as an example (most options shared between other compilers
icc and icpc.
To turn on debug symbols, adds line number of source file information:
$ ifort -g main.f90
To turn traceback to highlight where the program crashed. Provides line number of source file.
$ ifort -traceback main.f90
To force a strict standard compliance reduces issues due to compiler specific options being used that harms portability.
$ ifort -std95 main.f90
To strictly look for issues in code
$ ifort -C main.f90
Demonstration
Download the files
$ wget https://arcca.github.io/hpc-advanced/files/debug1/Makefile $ wget https://arcca.github.io/hpc-advanced/files/debug1/main.f90Look at the
Makefile, can you change the compilation options to turn on some of the compiler options. Update the time onmain.f90withtouch main.f90- runmakeagain. Try switching compilers and see how debug options work.Solution
The options should help identify issues. Updating the file should rebuild the executable. Just explore!
System settings
There are a few settings that can control the behaviour when compiled languages are run these are set using the ulimit
option.
To set the limit of core dumps (files generated when a program crashes) use
$ ulimit -c unlimited
To set the limit of the stack memory (important for Intel Fortran Compiler)
$ ulimit -s unlimited
Debuggers
There are a number of tools that can be used to look at problems at runtime for compiled codes such as gdb or ARM
Forge DDT.
gdb
Compile with -g to include debug symbols. Then run
$ ifort -g main.f90
$ gdb ./a.out
(gdb) run
gdb can usually be found where GNU compilers are available. It is very useful to print out other variables near to where the program crashes.
ARM Forge
ARM Forge contains a commercial debugger. It is loaded with a module
$ module load arm-forge
It is recommended to run the graphical debugger by installing the GUI interface on your local machine and connect remotely to Hawk via the software. A download from ARM website and look at the links in Remote Client Downloads
After installing the client you can setup a connection to Hawk using standard SSH connections and pointing to the Hawk
location for the version of ARM Forge, e.g. /apps/local/tools/arm/forge/20.0.3
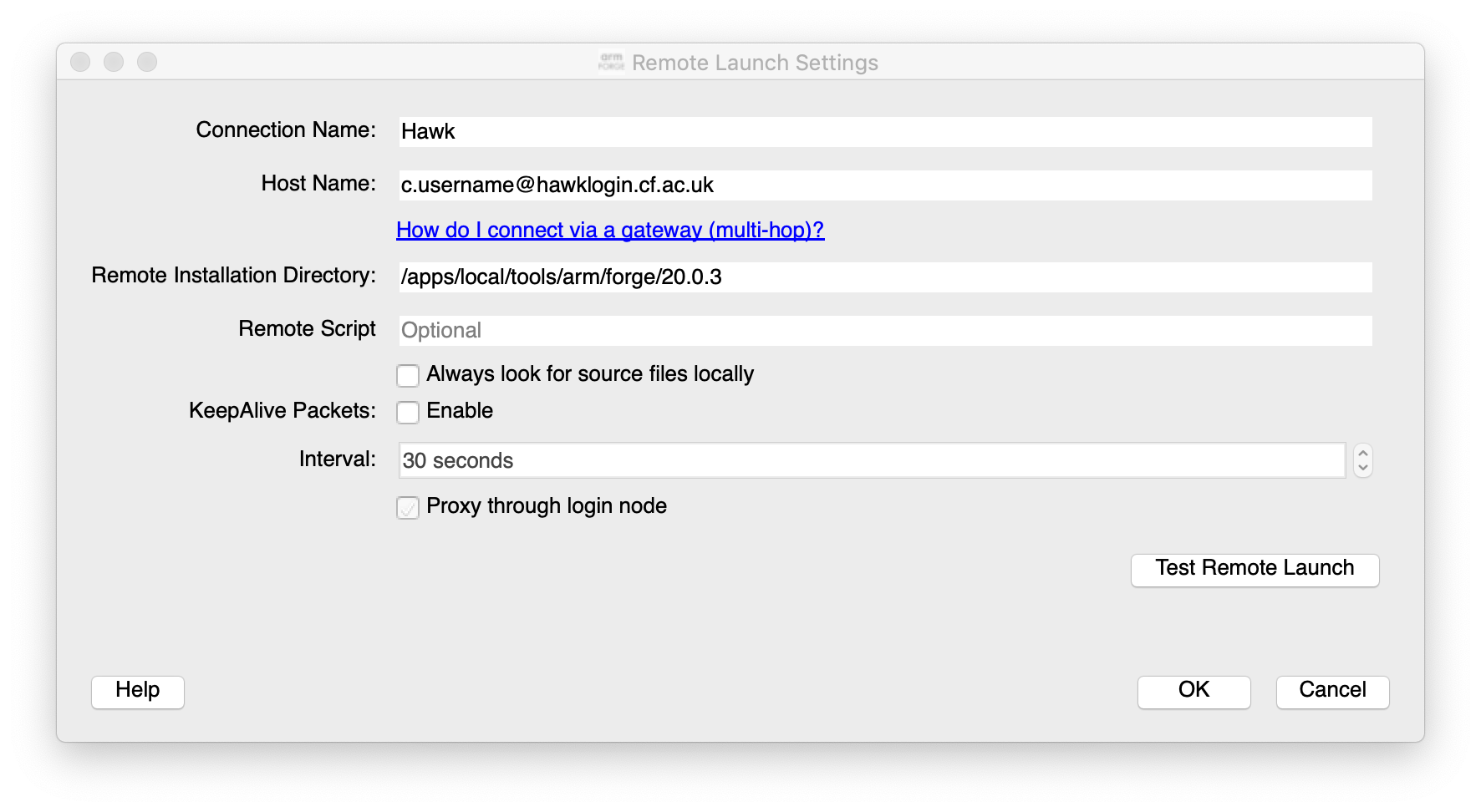
Options can be set for the job scheduler
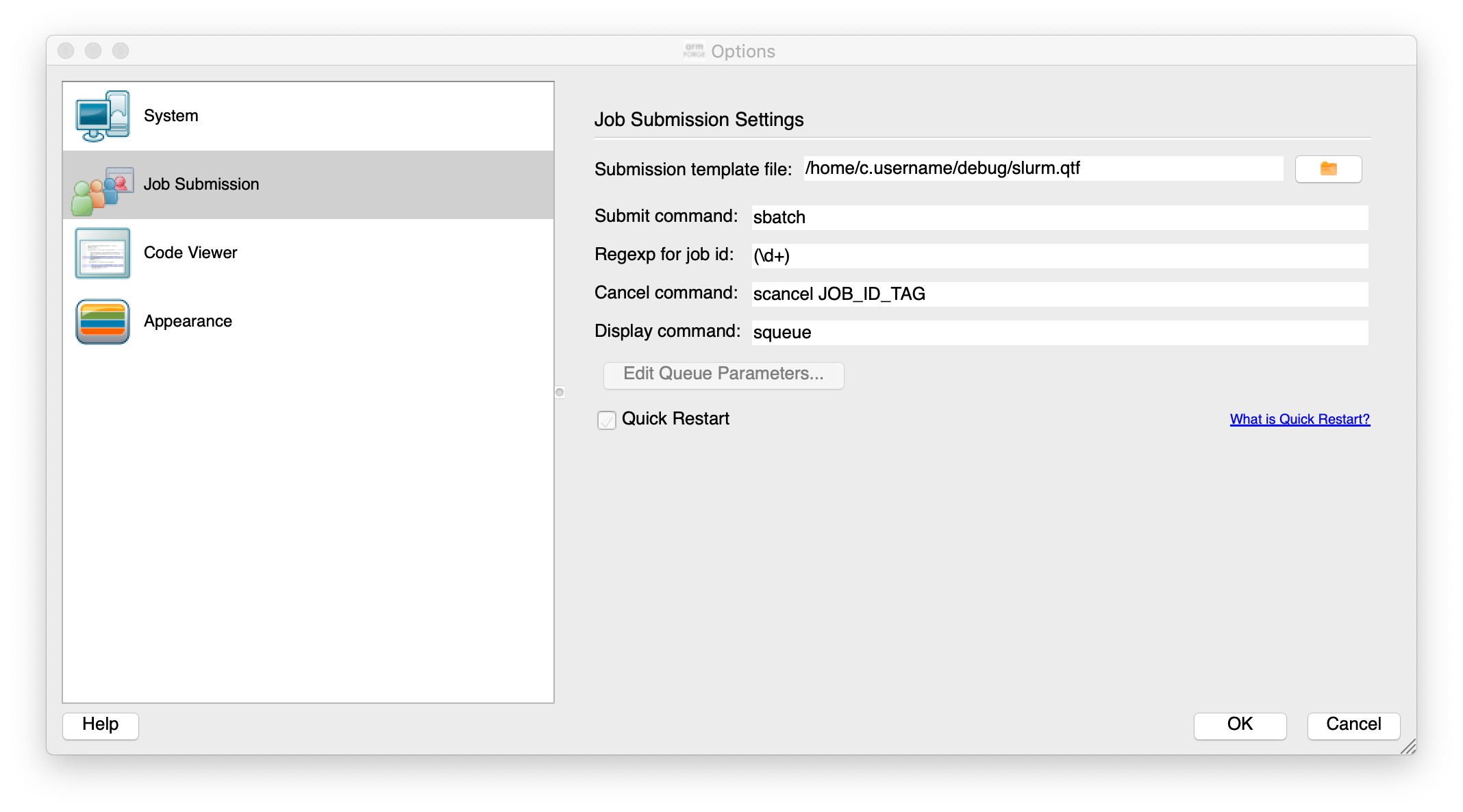
The important file to make sure it works is the template job submission script file. This is the file
/home/c.username/debug/slurm.qtf in the figure above and can be downloaded with
$ wget https://arcca.github.io/hpc-advanced/files/debug2/slurm.qtf
This can then be run and will be submitted to the queue and will then connect back to your desktop to allow you to step through the software.
If interested please get in touch if further help is required.
Python debugger Pdb
Python is already good at providing information on errors. If the program is not providing the correct answers then debugging would be useful.
The Pdb module is very useful for tracking program flow in Python and printing out variables to check state of the program.
Very similar to gdb.
To invoke Pdb, it can be applied to a Python script
$ python3 -m pdb myscript.py
Or near a location that requires by inserting in the Python script
import pdb; pdb.set_trace()
Demonstration
Download the files
$ wget https://arcca.github.io/hpc-advanced/files/debug3/Makefile $ wget https://arcca.github.io/hpc-advanced/files/debug3/main.f90 $ wget https://arcca.github.io/hpc-advanced/files/debug3/main.pyCompile the program with
make. Try running inside a debugger.Solution
Use
makeandgdbto explore the error. Usepdbfor Python.
Working with job schedulers
When running a debugger it can either be interactive or non-interactive. Interactive will require the job scheduler to
give you resource fairly quickly so a small example of the bug that requires small amount of resource will allow it to
queue less on Hawk. The dev partition can be used for short running jobs.
SLURM can provide an interactive session with
$ srun -n 1 -p compute --account=scwXXXX --pty bash --login
This will provide the user with a bash shell on the partition selected, e.g. compute in example above.
For non-interactive jobs, the debugger can be supplied with a script to print traceback or print a variable when it crashes. A core file can also be produced which contains a snapshot of memory at the point of crashing.
If software compiled with Intel compiler the following environment variable can be set in the job script before the program is run.
$ export decfort_dump_flag=y
This will produce a core file core.XXXX where XXXX is the process id of the crashed program.
A debugger such as gdb can be run on a login node with the executable and core file.
$ gdb ./a.out core.XXXX
Demonstration
Download the files
$ wget https://arcca.github.io/hpc-advanced/files/debug4/Makefile $ wget https://arcca.github.io/hpc-advanced/files/debug4/main.f90Look at the
Makefile, can you check that the compilation options to turn on some of the compiler options. See what happens when it is run.Solution
Set
decfort_dump_flag=yto create a core file and run withgdb ./a.out core.XXXX
Intel Inspector
OpenMP is a popular technique to parallelise code due to its simple method of using compiler directives to guide the compiler.
More information on OpenMP
We provide training on OpenMP for users wanting further information on how to use it. Please check recent training notices.
The easy nature of adding OpenMP can also lead to common mistakes such as race conditions on threads reading and writing to the same variable. Intel Inspector checks the code for threading issues. An example of it highlighting possible issues can be found in the Github issue for the COVID-19 CovidSim microsimulation model developed by the MRC Centre for Global Infectious Disease Analysis.
Intel Inspector can be loaded with the module intel-psx
$ module load intel-psx
This loads the complete Intel Parallel Studio software suite.
Then the application, e.g. my_app.exe, you want to debug can be run with
$ inspxe-cl -collect ti2 -result-dir ./myResult1 -- my_app.exe
This will output the collected data from the application in myResult1 directory. The -collect option can be varied
depending on what needs to be collected.
$ inspxe-cl -collect-list
Available analysis types:
Name Description
mi1 Detect Leaks
mi2 Detect Memory Problems
mi3 Locate Memory Problems
ti1 Detect Deadlocks
ti2 Detect Deadlocks and Data Races
ti3 Locate Deadlocks and Data Races
Intel Inspector is currently free at time of writing but it can be run remotely n Hawk. Due to the GUI it is recommended to request access to the VNC server (a more efficient method of running graphical windows from a remote machine).
$ inspxe-gui
And load the files generated from the collection stage.
If further information is required please get in touch.
Summary
This has been a short introduction to debuggers and common methods to analyse and identify the bug to fix.
Key Points
Bugs can come in all shapes and sizes, know your tools!
Optimisation
Overview
Teaching: 45 min
Exercises: 15 minQuestions
Why is more job running so slowly?
What is a GPU and how do I use one?
Where should I read and write my data?
What libraries should I use for X?
Objectives
Profile and understand different between walltime and cputime.
Understand what a GPU is and how it can be used.
Understand all the different filesystems on the system.
Look for existing libraries that provide the function you need.
When looking to speed up code there are 2 parts of the code that need to be understood:
- The parallel section - code that benefits from multiple processors.
- The serial section - code that is performed by one processor.
Amdahl’s Law can be used to describe the performance. The serial sections of code will always restrict the possibility of perfect scaling. This is covered further in OpenMP and MPI courses.
Whilst analysing code and improving the performance is good practice, it really only makes a difference for developers. For users it is important to be able to know the options that can speed up their jobs. GPUs can provide a simple method for users to benefit from if the software supports them. GPUs can greatly speed up common tasks such as linear algebra operations.
Another aspect of performance is the I/O. This usually related to the filesystem performance but also be network performance can impact applications using MPI.
GPUs
Hawk, as of July 2020, contains 2 types of Nvidia GPUs.
- Nvidia V100
- Ideal for machine learning with Tensor Core technology
- Dual cards on
gpu_v100partition.
- Nvidia Tesla P100
- General purpose GPU with still good performance.
- Dual cards on
gpupartition
SLURM requires the job to request both the correct partition and how many GPUs to use. For example
$ srun -n 1 -p gpu --gres=gpu:1 --pty bash --login
This will ask for 1 CPU and 1 GPU card to use. This sets CUDA_VISIBLE_DEVICES to tell software to only use the GPU
cards given to it.
To benefit from GPUs the code requires explicit instructions where it will copy and process the data on the GPU. Not all work benefits from GPUs but where it is possible it usually results in great gains in performance.
Example
Matlab can use GPUs. Matlab is available with module load matlab. For example run Matlab and run gpuDevice() to list the GPU device.
Matlab example
Run Matlab and find out what GPUs are available on both
gpuandgpu_v100partition.Solution
Request a SLURM interactive system with
$ srun --account=scw1148 -n 1 -p gpu --gres=gpu:1 --pty bash --loginRun Matlab with
matlab -nodisplayand typegpuDevice()
Pytorch is a popular machine learning framework. This is available with module module load
pytorch but can also be installed by the user (see previous session. Pytorch will need some
data files. These can be downloaded on the login node either by running the example script with --epochs=0 or within Python such as downloading the MNIST dataset with
import torchvision
torchvision.datasets.MNIST(root="data", download=True)
There are a number of example tutorial scripts included in the repository at Github but may be version dependent.
Pytorch example
Download
mnist.pyfrom$ wget https://arcca.github.io/hpc-advanced/files/opt1/mnist.pyThen
module load pytorchand download the data before running on SLURM$ python mnist.py --epochs=0Time each run with
--no-cudafor non-GPU code and with no options to use default GPU.Solution
Make sure in the same directory downloaded data and request interactive session
$ srun --account=scw1148 -n 1 -p gpu --gres=gpu:1 --pty bash --loginThen run with
time$ time python mnist.py --no-cuda $ time python mnist.py
Further GPU advice
GPUs can be used for many tools from Molecular simulation to Photogrammetry software. Just check the documentation for the application for GPUs.
There is also the option of Singularity (see previous session along with Nvidia NGC to lookup and download software that benefits from GPUs.
Filesystems
On Hawk, there are 3 main filesystems
/scratch- Lustre parallel filesystem./home- NFS/tmp- Local filesystem on each node. Small compared to others.
Jobs should be run on Lustre unless for specific reasons. Hawk benefits from new Lustre features such as Progressive File Layouts to simplify some of the previous issues with performance.
Other filesystems on HPC
There are many types of filesystems that might be encountered for particular use cases. GPFS is similar to Lustre while HDFS is for data analytics.
Lustre
What is /scratch? The filesystem consists of a number of servers. Each server provides places to store data (OSTs)
and the metadata of the data (MDTs). These can be listed running:
$ lfs osts
$ lfs mdts
Hawk now has 40 OSTs serving 1.2 PB of storage. There is 1 MDT serving the metadata of the data. With only 1 metadata target serving information about files, accessing many small files on Lustre delivers very poor performance. For a simple demonstration run
$ time /bin/ls /scratch
Can produce
real 0m0.011s
and
$ time ls /scratch
Can produce
real 0m0.030s
The difference between the commands is ls tends to be an alias to colorise the output and it will lookup the metadata
of the files which is slow on Lustre. E.g.
$ alias
Will show
alias ls='ls --color=auto'
Metadata on other systems
Repeat on other filesystems on Hawk such as
/tmpand/home.
With 40 OSTs it should be possible to write out data in parallel upto 40 OSTs in parallel if the code supports it.
For power users, the way a file is divided across the OSTs can be seen with
$ lfs getstripe /scratch/c.username/my_file
NFS
NFS is a server/client design where all data is served from one server across all clients (compared to Lustre with many servers and storage devices). Another aspect to remember is caching, /home is NFS based and performing an operation such as ls will be slow the
first time and faster the next time. Performance is not consistent.
We DO NOT recommend running jobs on /home.
/tmp
/tmp is the local filesystem on each node. It is small (only in the GBs) and shared with other users. However for
some operations such as small file I/O it can be useful to use, however this tends to be quite rare.
General advice
- ALWAYS use
/scratch/for large files input and output. - For smaller files possible to use
/homeor/tmpbut only a few jobs at a time. - Write files in large blocks of data. Do not write and flush output since it is a slow way of writing data.
- For Intel Fortran Compiler use
export FORT_BUFFERED=ywhen running the code.
Profiling code
Profiling the application is critical in highlighting what parts of the code need to be targetted for optimisation.
For Intel Fortran Compiler (similar to C and C++) use the following:
$ ifort -g -pg main.f90
Then run the executable ./a.out and this will produce gmon.out and run
$ gprof ./a.out gmon.out
With Python, the following can be used
$ python -m cProfile [-o output] [-s sort] main.py
Optimisation
Obtain the examples at
$ wget https://arcca.github.io/hpc-advanced/files/opt2/Makefile $ wget https://arcca.github.io/hpc-advanced/files/opt2/main.f90 $ wget https://arcca.github.io/hpc-advanced/files/opt2/main.pyRun them with the relevant optimisation tool.
Solution
Load the Intel Compiler with
module load compiler/inteland thenmakeand thengprof ./main gmon.out. Output will show the timings.For Python load the version of Python
module load pythonand thenpython3 -m cProfile main.pyand check output for timings for each function.Arrays are stored in a certain way and if accessed in sequence then performance is fast, if accessed by jumping around the array then performance bad - CPU cache is not being used efficiently.
ARM Forge
ARM Forge, just like with debugging, has an optimiser as well. It is recommended to use the local GUI. This is available as a download from ARM website and look at the links in Remote Client Downloads
The optimiser, MAP, allows you to run the program either directly or via a job scheduler. There is also an option to load a file that contains the sample data from a previous run of the optimiser on Hawk.
Please get in contact if interested.
Summary
It is worth spending some time looking at software and seeing what options there are such as GPUs. Use /scratch
unless for some demonstratable performance reason. Please get in contact if you feel your jobs are not working.
Key Points
Optimising jobs benefits you AND the whole community using the system.
Do not reinvent the wheel if you need common functionality in your code.
Scheduler advice
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What possible methods are there to run my job in the scheduler?
What information is available for the user?
How does a scheduler allocate resource?
Objectives
Understand many ways to run jobs in a scheduler.
Use the tools in the scheduler to find useful information.
Understand the decisions a scheduler has to make when allocating resource.
Much of the scheduler advice for performance can now be found in previous training. However general advice is
- Job arrays are useful for repetative tasks where only the input file changes.
- Find from SLURM how your job has performed in the scheduler with
sacct.
For developers you can use libraries such as:
- NetCDF for gridded data
- Intel MKL for linear algebra problems
Finding job efficiency
Using
sacctfind the job efficiency for a SLURM job.Solution
Use
sacct -j <jobid> -o "CPUTime, UserCPU"and compare difference.
When using AMD nodes on Hawk the MKL library is setup to override the standard options and force it to use AVX2 through
setting an environment variable. Try not to change the environment variable MKL_DEBUG_TYPE
Finally, please get in touch - ARCCA is here to help you are a researcher to perform you work efficiently and effectively.
Key Points
The scheduler can only allocate resource with the information given.