Introduction
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What are some common terms in parallel computing?
Why use parallel computing?
Objectives
Familiarize with common hardware and software terms in parallel computing
Obtain a general overview of the evolution of multi core computers in time
Terminology
Hardware
- CPU = Central Processing Unit
- Core = Processor = PE (Processing Element)
- Socket = Physical slot to fit one CPU.
- Node = In a computer network typically refers to a host computer.
Software
- Process (Linux) or Task (IBM)
- MPI = Message Passing Interface
- Thread = some code / unit of work that can be scheduled
- OpenMP = (Open Multi-Processing) standard for shared memory programming
- User Threads = tasks * (threads per task)
A CPU is a computer’s Central Processing Unit that is in charge of executing the instructions of a program. Modern CPUs contain multiple cores that are physical independent execution units capable of running one program thread. CPUs are attached to a computer’s motherboard via a socket and high-end motherboards can fit multiple CPUs using multiple sockets. A group of computers (hosts) linked together in a network conform a cluster in which each individual computer is referred as a node. Clusters are typically housed in server rooms, as is the case for Hawk supercomputer located at the Redwood Building in Cardiff University.

Why go parallel?
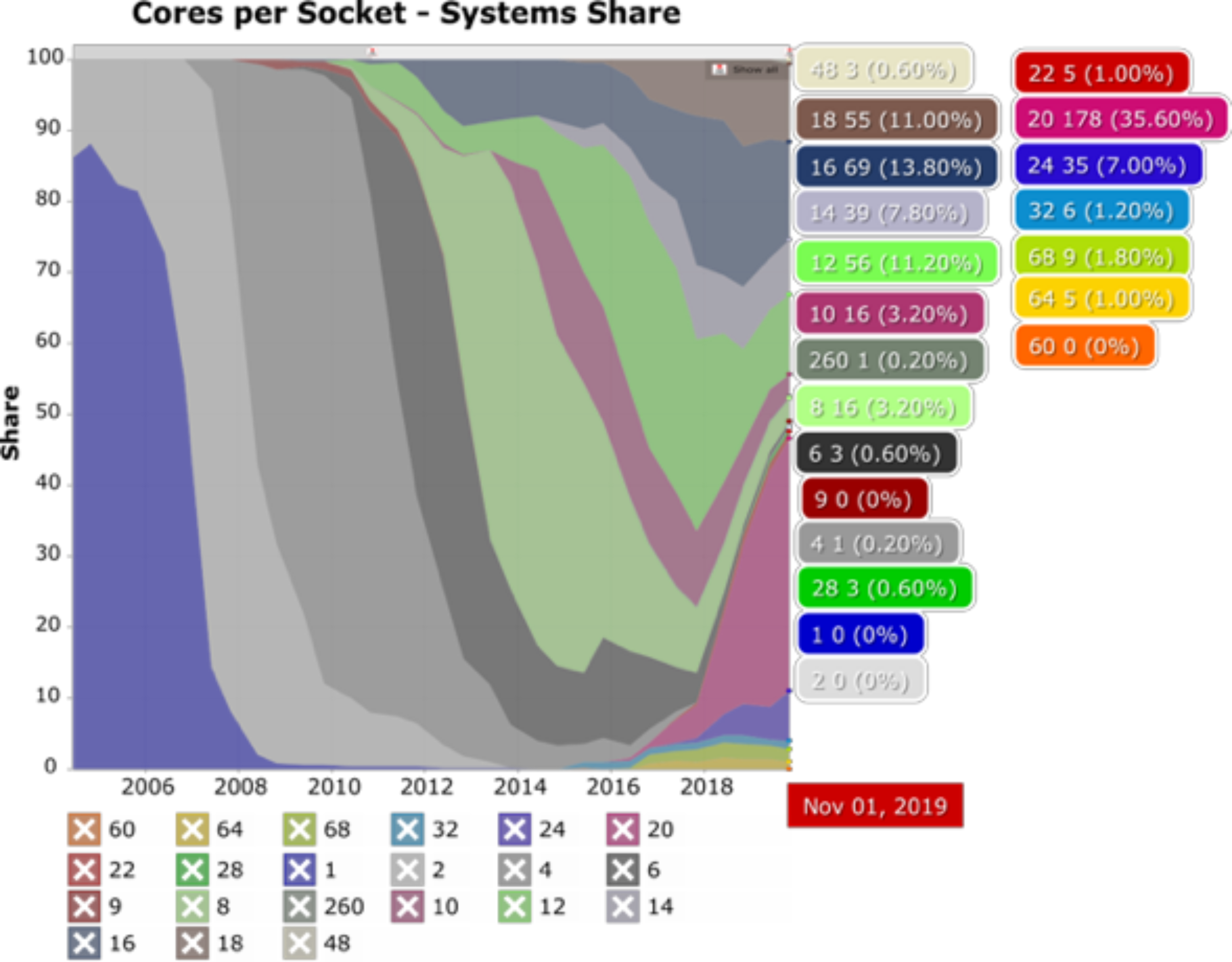
Over time the number of cores per socket have increased considerably, making parallel work on a single computer possible and parallel work on multiple computers even more powerful. The following figure shows the change in market share of number of Cores per Socket as a function of time. In the early 2000’s it was more common for systems to have a single core per socket and just a few offered a dual core option. Fast forward to late 2019 and the landscape has changed a lot with several options now available. Systems with 20 cores per socket represented 35% of the market (as with Hawk’s Skylake CPUs) while systems with 32 cores per socket represented only 1.2% (as with Hawk’s AMD Epyc Rome CPUs). Will this trend continue? It is likely, and therefore, it is worth investing in learning how parallel software works and what parallelization techniques are available.
Key Points
A core is a physical independent execution unit capable of running one program thread.
A node is another term to refer to a computer in a network.
In recent years computers with several cores per CPU have become the norm and are likely to continue being into future.
Learning parallelization techniques let you exploit multi core systems more effectively
Single vs Parallel computers
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What we understand as a single computer?
What we understand as a parallel computer?
What are some of the key elements that determine a computer’s performance?
Objectives
Understand the difference between single and paralllel computers
Identify some key elements that determine a computer’s performance
Single computers

A Central Processing Unit, or CPU, is a piece of hardware that enables your computer to interact with all of the applications and programs installed in a computer. It interprets the program’s instructions and creates the output that you interface with when you’re using a computer. A computer CPU has direct access to the computer’s memory to read and write data necessary during the software execution.
As CPUs have become more powerful, they have allowed to develop applications with more features and capable of handling more demanding tasks, while users have become accustomed to expecting a nearly instantaneous response from heavy multitasking environments.
Make it go faster
When we talk about a computer’s speed, we typically are referring to its performance when interacting with applications. There are three main factors that can impact a computer’s performance:
-
Increase clock speed: Clock speed refer to the number of instructions your computer can process each second and is typically measured in GHz, with current gaming desktop computers in the order of 3.5 to 4 GHz.
-
Increase the number of CPUs: Ideally, we would like to have the best of both worlds, as many processors as possible with clock speed as high as possible, however, this quickly becomes expensive and limiting due to higher energy demand and cooling requirements.
-Available vector instructions: Modern CPUs are equipped with the capacity to apply the same instruction to multiple data points simultaneously, this is known as SIMD instructions.
Did you know?
Hawk has two types of CPUs available:
- Xeon Gold 6148 (Skylake) at 2.4GHz clock speed, 20 cores per node and support for AVX512 instructions.
- AMD Epyc Rome 7502 at 2.5 GHz clock speed, 32 cores per node and support for AVX256 instructions.
Find out more here: https://portal.supercomputing.wales/index.php/about-hawk/
Parallel computers

Since Intel Pentium 4 back in 2004, which was a single core CPU, computers have gradually increased the number of cores available per CPU. This trend is pushed forward by two main factors: 1) a physical limit to the number of transistors that can be fit in a single core, 2) the speed at which these transistors can change state (on/off) and the related energy consumption.
Reducing a CPU clock speed reduces the power consumption, but also its processing capacity. However, since the relation of clock speed to power consumption is not linear, effective gains can be achieved by adding multiple low clock speed CPUs.
Although CPU developers continue working towards increasing CPU clock speeds by engineering, for example, new transistor geometries, the way forward to achieve optimal performance is to learn to divide computations over multiple cores, and for this purpose we could keep in mind a couple of old sayings:
“Many hands make light work”
“Too many cooks spoil the broth”
Thinking about programming
- Decompose the problem
- Divide the algorithm (car production line) - Breaking a task into steps performed by different processor units.
- Divide the data (call centre) - If well defined operations need to be applied on independent pieces of data.
- Distribute the parts
- work in parallel
- Considerations
- Synchronisation
- Communicate between processor
- Hardware issues
- What is the architecture being used?
Key Points
Clock speed and number of cores are two key elements that affect a computer’s performance
A single computer is typically understood as a single core CPU
A parallel computer is typically understood as a multi core CPU
Multiple cores in a parallel computer are able to share a CPU’s memory
Shared vs Distributed Memory
Overview
Teaching: 15 min
Exercises: 0 minQuestions
What is shared memory?
What is distributed memory?
Objectives
Understand the differences between shared and distributed memory
How data is managed by processors in shared and distributed memory systems
Awareness of key performance points when working with parallel programs: granularity and load balancing.
Shared memory

As the name suggests, shared memory is a kind of physical memory that can be accessed by all the processors in a multi CPU computer. This allows multiple processors to work independently sharing the same memory resources with any changes made by one processor being visible to all other processors in the computer.
OpenMP is an API (Application Programming Interface) that allows shared memory to be easily programmed. With OpenMP we can split the work of the calculation by dividing the work up among available processors. However, we need to be careful as to how memory is accessed to avoid potential race conditions (e.g. one processor changing a memory location before another has finished reading it).
Distributed memory

In comparison with shared memory systems, distributed memory systems require network communication to connect memory resources in independent computers. In this model each processor runs its own copy of the program and only has direct access to its private data which is typically a subset of the global data. If the program requires data to be communicated across processes this is handled by a Message Passing Interface in which, for example, one processor sends a message to another processor to let it know it requires data in its domain. This requires a synchronization step to allow all processors send and receive messages and to prepare data accordingly.
How it works?
A typical application is to parallelize matrix and vector operations. Consider the following example in which a loop is used to perform vector addition and multiplication. This loop can be easily split across two or more processors since each iteration is independent of the others.
DO i = 1, size
E(i) = A(i) + B(i)
F(i) = C(i)*D(i)
END DO
Consider the following figure. In a shared memory system all processors have access to a vector’s elements and any modifications are readily available to all other processors, while in a distributed memory system, a vector elements would be decomposed (data parallelism). Each processor can handle a subset of the overall vector data. If there are no dependencies as in the previous example, parallelization is straightforward. Careful consideration is required to solve any dependencies, e.g. A(i) = B(i-1) + B (i+1).

The balancing act
In practice, highly optimized software tends to use a mixture of distributed and shared memory parallelism called “hybrid” where the application processes use shared memory within the node and distributed memory across the network.
The challenge is to balance the load across the nodes and processors giving enough work to everyone. The aim is to keep all tasks busy all the time since an idle processor is a waste of resources.
Load imbalances can be caused, for example:
- by array dimensions not being equally divided. Compilers can address these issues through optimization flags, that allow, for example, to collapse loops, changing a matrix A(m,n) to a vector A(n*m) that is easier to distribute.
- Different calculations for different points – e.g. different governing equations applied to sea or land points on a weather forecasting model.
- The amount of work each processor need to do cannot be predicted - e.g. in adaptive grid methods where some tasks may need to refine or coarse their mesh and others don’t.
Granularity
Granularity refers in parallel computing to the ratio between communication and computation, periods of computation are separated by periods of communication (e.g. synchronization events).
There are two types of approaches when dealing with load balancing and granularity parallelization:
-
“Fine-grain” - where many small workloads are done between communication events. Small chunks of work are easier to distribute and thus help with load-balancing, but the relatively high number of communication events cause an overhead that gets worse as number of processors increase.
-
“Coarse-grain” - where large chunks of workload are performed between communications. It is more difficult to load-balance but reduces the communication overhead
Which is best depend on the type of problem (algorithm) and hardware specifications but in general a “Coarse-grain” approach due to its relatively low communication overhead is considered to have the best scalability.
Steps to parallel code
- Familiarize with the code and identify parts which can be parallelized
- This typically requires high degree of understanding
- Decompose the problem
- Functional (shared) or data (distributed), or both
- Code development
- Choose a model to concentrate on
- Data dependencies
- Divide code where for task or communication control
- Compile, Test, Debug, Optimize
Key Points
Shared memory is the physical memory shared by all CPUs in a multi-processor computer
Distributed memory is the system created by linking the shared memories of different computers
It is important to distribute workload as equally as possible among processors to increase performance
Using shared memory
Overview
Teaching: 15 min
Exercises: 5 minQuestions
What is OpenMP?
How does it work?
Objectives
Obtain a general view of OpenMP history
Understand how OpenMP help parallelize programs
Brief history
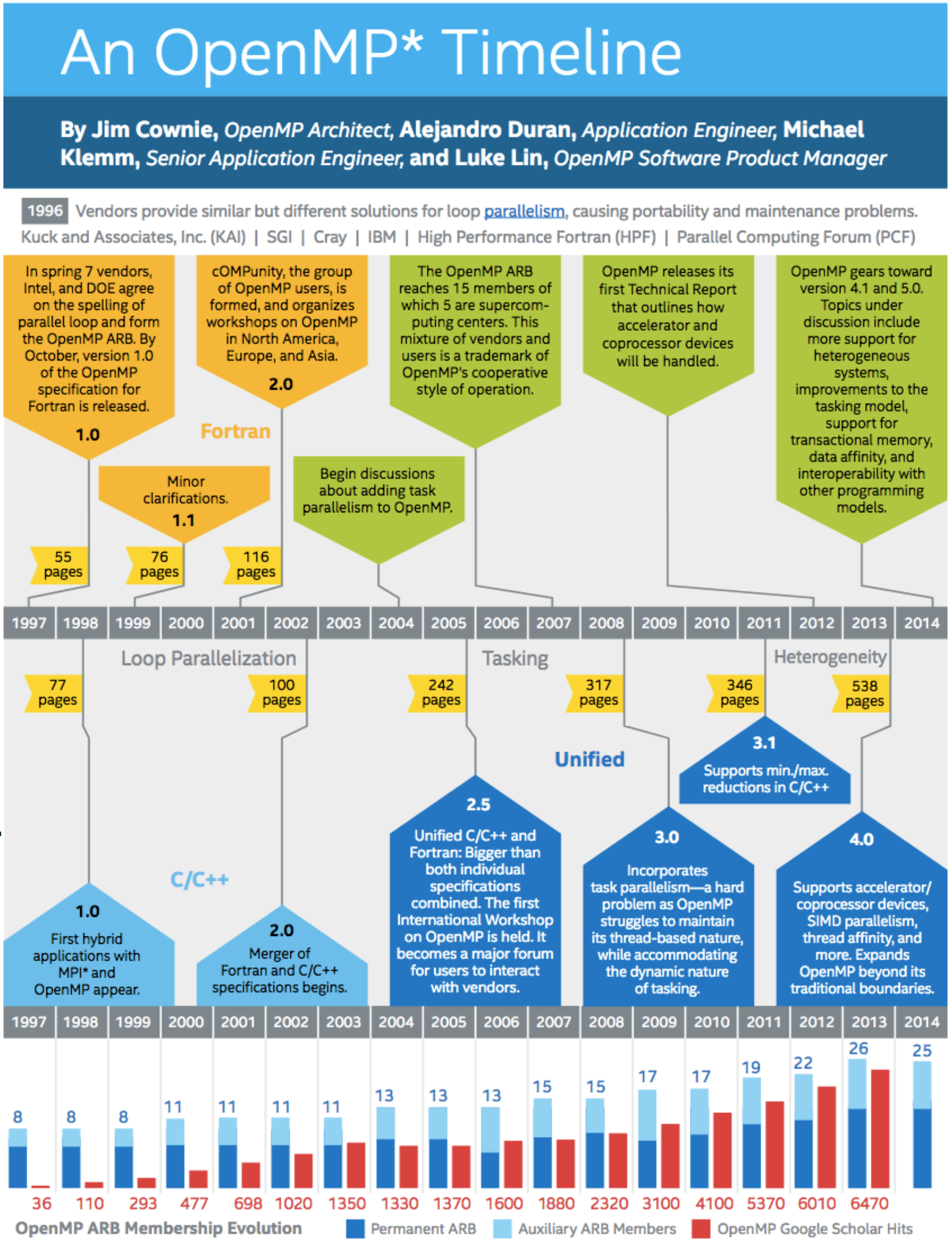
You can consult the original in Intel’s Parallel Universe magazine.
In 2018 OpenMP 5.0 was released, current latest version is OpenMP 5.1 released November 2020.
What is OpenMP
The OpenMP Application Program Interface (OpenMP API) is a collection of compiler directives, library routines, and environment variables that collectively define parallelism in C, C++ and Fortran programs and is portable across architectures from different vendors. Compilers from numerous vendors support the OpenMP API. See http://www.openmp.org for info, specifications, and support.
OpenMP in Hawk
Different compilers can support different versions of OpenMP. You can check compatibility by extracting the value of the _OPENMP macro name that is defined to have the decimal value yyyymm where yyyy and mm are the year and month designations of the version of the OpenMP API that the implementation supports. For example, using GNU compilers in Hawk:
~$ module load compiler/gnu/9/2.0 ~$ echo | cpp -fopenmp -dM | grep -i open #define _OPENMP 201511Which indicates that GNU 9.2.0 compilers support OpenMP 4.5 (released on November 2015). Other possible versions are:
GCC version OpenMP version 4.8.5 3.1 5.5.0 4.0 6.4.0 4.5 7.3.0 4.5 8.1.0 4.5 9.2.0 4.5
OpenMP overview
-
OpenMP main strength is its relatively easiness to implement requiring minimal modifications to the source code that automates a lot of the parallelization work.
-
The way OpenMP shares data among parallel threads is by creating shared variables.
-
If unintended, data sharing can create race conditions. Typical symptom: change in program outcome as threads are scheduled differently.
-
Synchronization can help to control race conditions but is expensive and is better to change how data is accessed.
-
OpenMP is limited to shared memory since it cannot communicate across nodes like MPI.
How does it work?
Every code has serial and (hopefully) parallel sections. It is the job of the programmer to identify the latter and decide how best to implement parallelization. Using OpenMP this is achieved by using special directives (#pragma)s that mark sections of the code to be distributed among threads. There is a master thread and several slave threads. The latter execute the parallelized section of the code independently and report back to the master thread. When all threads have finished, the master can continue with the program execution. OpenMP directives allow programmers to specify:
- the parallel regions in a code
- how to parallelize loops
- variable scope
- thread synchronization
- distribution of work among threads

Fortran:
!$OMP PARALLEL DO PRIVATE(i)
DO i=1,n
PRINT *, "I am counter i = ", i
ENDDO
!$OMP END PARALLEL DO
C:
#pragma omp parallel for
for (i=0; i < N; i++)
printf("I am counter %d\n", i);
Further reading
https://www.openmp.org/resources/openmp-compilers-tools/
Very comprehensive tutorial:
https://hpc-tutorials.llnl.gov/openmp/
Key Points
OpenMP is an API that defines directives to parallelize programs written in Fortran, C and C++
OpenMP relies on directives called pragmas to define sections of code to work in parallel by distributing it on threads.
My First Thread
Overview
Teaching: 20 min
Exercises: 10 minQuestions
How to use OpenMP in C and Fortran?
OpenMP parallel and loop constructs
Objectives
Identify libraries that enable OpenMP functions
Identify compiler flags to enable OpenMP support
Familiarize with OpenMP main constructs
Setting up
In principle, the exercises on this training lessons can be done on any computer with a compiler that supports OpenMP, but they have been tested on Cardiff University Linux-based supercomputer “Hawk” using Intel compilers 2017.
Access to the system is necessary to undertake this course. It is assumed that attendees have a user account or have received a guest training account.
Please follow the instructions below to obtain some example scripts:
- Download arc_openmp.zip and extract somewhere on Hawk.
- Extract the zip file and check the extracted directory
For example:
$ wget https://arcca.github.io/Introduction-to-Parallel-Programming-using-OpenMP/data/arc_openmp.zip
$ unzip arc_openmp.zip
$ ls arc_openmp
A node reservation is created in partition c_compute_mdi1. To access it users need to specify in their job scripts:
#SBATCH --reservation=training
#SBATCH --account=scw1148
Using OpenMP
In order to use them, OpenMP function prototypes and types need to be included in our source code by importing a header fileomp.h (for C,C++), a module omp_lib (for Fortran 90) or a file named omp_lib.h (for Fortran 77).
Include OpenMP in your program
When using OpenMP in Fortran 77:
INCLUDE "omp_lib.h"Declare functions at start of code e.g.
INTEGER OMP_GET_NUM_THREADSWhen using Fortran 90:
USE omp_libWhen using C or C++:
#include<omp.h>
In order to enables the creation of multi-threaded code based on OpenMP directives, we need to pass compilation flags to our compiler:
Compiling OpenMP programs
For Fortran codes:
~/openmp/Intro_to_OpenMP.2020/fortran$ ifort –qopenmp –o first first.f90For C codes:
~/openmp/Intro_to_OpenMP.2020/c$ icc –qopenmp –o first first.c
My first thread
In this first example we will take a look at how to use OpenMP directives to parallelize sections of our code. But before been able to compile, we need a compiler with OpenMP support. Hawk provides several options but for this training course we will use Intel compilers 2017:
~$ module load compiler/intel/2017/7
Our first example looks like this (there is an equivalent Fortran code too available to you):
int main()
{
const int N = 10;
int i;
#pragma omp parallel for
for(i = 0; i < N; i++)
{
printf("I am counter %d\n", i);
}
}
#pragma (and !$OMP in the Fortran version) is an OpenMP directive that indicates to the compiler that the following section (a for loop in this case) needs to be parallelized. In C and C++ the parallel section is delimited by loop’s scope while in Fortran it needs to be explicitly marked with !$OMP END.
Random threads
- Try running the program above. What do you notice?
- Run it a number of times, what happens?
- What happens if you compile it without the –qopenmp argument?
The PARALLEL construct
This is the fundamental OpenMP construct for threading operations that defines a parallel region. When a thread encounters a parallel construct, a team of threads is created to execute the parallel region. The thread that encountered the parallel construct becomes the master thread of the new team, with a thread number of zero for the duration of the new parallel region. All threads in the new team, including the master thread, execute the region. The syntax of the parallel construct is as follows:
Fortran:
!$OMP PARALLEL [clause,[clause...]]
block
!$OMP END PARALLEL
C, C++:
#pragma parallel omp [clause,[clause...]]
{
block
}
Clauses
OpenMP is a shared memory programming model where most variables are visible to all threads by default. However, private variables are necessary sometimes to avoid race conditions and to pass values between the sequential part and the parallel region. Clauses are a data sharing attributes that allow data environment management by appending them to OpenMP directives
For example, a private clause declares variables to be private to each thread in a team. Private copies of the variable are initialized from the original object when entering the parallel region. A shared clause specifically shares variables among all the threads in a team, this is the default behaviour. A full list of clauses can be found in OpenMP documentation.
Loop constructs
The DO (Fortran) directive splits the following do loop across multiple threads.
!$OMP DO [clause,[clause...]]
do_loop
!$OMP END DO
Similarly, the “for” (C) directive splits the following do loop across multiple threads. Notice that no curly brackets are needed in this case.
#pragma omp for [clause,[clause...]]
for_loop
OpenMP clauses can also define how the loop iterations run across threads. They include:
SCHEDULE: How many chunks of the loop are allocated per thread.
Possible options are:
schedule(static, chunk-size): Gives threads chunks of sizechunk-sizein circular order around thread id.chunk-sizeis optional, default is to divide up work to give one chunk to each thread.schedule(dynamic, chunk-size): Gives threads chunks of sizechunk-sizeand when complete gives another chunk until complete.chunk-sizeis optional, default is 1.schedule(guided, chunk-size): Minimum size given bychunk-sizebut size of chunk initially is given by unassigned iterations divided by number of threads.schedule(auto): Decision is given to the compiler of runtime.
Auto schedule can be set with OMP_SCHEDULE at runtime or omp_set_schedule in the code at compile time.
If no SCHEDULE is given then compiler dependent default is used.
ORDERED: Loop will be executed as it would in serial, i.e. in order. These clauses are useful when trying to fine-tune the behaviour of our code, but caution should be observed since they can introduced unwanted communication overheads.
Working with private variables and loop constructs
Consider the previous example. What happens if you remove the for (DO) clause in our OpenMP construct? Is this what you expected? What happens if you add the private(i) (DO(i)) clause? How does the output changes? Why?
WORKSHARE
The WORKSHARE construct is a Fortran feature that consists of a region with a single structure block (section of code). Statements in the work share region are divided into units of work and executed (once) by threads of the team. A good example for block would be array assignment statements (I.e. no DO)
!$OMP WORKSHARE
block
!$OMP END WORKSHARE
Thread creation
Creating OpenMP threads add an overhead to the program’s overall runtime and for small loops this can be expensive enough that it doesn’t make sense to parallelize that section of the code. If there are several sections of code that require threading, it is better to parallelize the entire program and specify where the workload should be distributed among the threads team.
#pragma omp parallel for ...
for (int i=0; i<k; i++)
nwork1...
#pragma omp parallel for ...
for (int i=0; i<k; i++)
nwork2...
Is better to:
#pragma omp parallel ...
{
#pragma omp for ...
for (int i=0; i<k; i++)
nwork1...
#pragma omp for ...
for (int i=0; i<k; i++)
nwork2...
}
Key Points
Importing
omp.hin C,C++,omp_libin Fortran 90 andomp_lib.hin Fortran 77 allows OpenMP functions to be used in your codeOpenMP construct parallel in C,C++ and PARALLEL instructs the compiler to create a team of threads to distribute the region of the code enclosed by the construct
Basic thread control
Overview
Teaching: 10 min
Exercises: 5 minQuestions
How to obtain OpenMP threads’ IDs?
What is the barrier OpenMP construct?
What is the master OpenMP construct?
Objectives
Learn how to identify OpenMP treads by using IDs
Familiarize with OpenMP barrier and master constructs and their use
Hello World with OpenMP
In this example we will create a simple OpenMP program that does the following:
- Creates a parallel region
- Each thread in the parallel region obtains and prints its unique thread along with a “Hello World” message
- Only the master will print the total number of threads
// Load the OpenMP functions library
#include<omp.h>
int main()
{
int nthreads, tid;
// Fork a team of threads, with private versions of the declared variables.
// #pragma omp parallel private(nthreads, tid)
// {
// Get the thread number and print it
tid = omp_get_thread_num();
printf("Hello World from thread number %d\n", tid);
// Only the master thread does the following
// #pragma omp barrier
// #pragma omp master
// {
if (tid == 0)
{
nthreads = omp_get_num_threads();
printf("Number of threads = %d\n", nthreads);
}
// }
// End of pragma, disband all but the master thread
//}
return 0;
}
From serial to parallel.
The first thing to notice in the example above is the commented lines that include the OpenMP directives. As it stands, this program will work in serial mode. Go ahead and compile it:
~/openmp/Intro_to_OpenMP.2019/c$ icc -qopenmp -o hello hello.cWhat is the output when you run it. What happens if you remove the compiler flag -qopenmp?
As you have noticed, in the program we are making use of a couple of OpenMP routines to identify the threads’ unique ID numbers and the maximum threads available. Without the flag -qopenmp the compiler doesn’t understand these functions and therefor throws an error.
Try uncommenting lines 8,9 and 26. Recompile and run the program. What happens in this case? Why?
By adding a few lines we were able to define a region in our code to be distributed among threads. In this region we are defining as private two variables nthreads and tid so that each thread will have their own copies.
#pragma omp parallel private(nthreads, tid)
{
...
}
Barriers
The barrier construct specifies an explicit barrier at the point at which the construct appears. The barrier construct is a stand-alone directive. It defines a point in the code where threads will stop and wait for all other threads to reach that point. This is a way to guarantee calculations performed up to that point have been completed.
Using barriers
Continuing with the above example. We noticed that all threads print their ID number and master prints additionally the total number of threads. However, we can not predict at which point we will obtain the total number. If we wanted to make sure to print the total number of threads in the very last line, we could a barrier.
Try uncommenting line 15 in the code. Recompile and run the program. What happens this time?
Master
So far in our example we have been using a conditional if statement to obtain and print the total number of threads, since we know the master thread ID is 0. However, OpenMP gave us a master construct that allow us to specify that a structured block to only be executed by the master thread of a team.
Using the master
Keep working in our hello world example. Uncomment line 16 and comment out line 18. Were there any changes?
Key Points
OpenMP threads can be identified by querying their ID using OpenMP functions
OpenMP barrier construct allow us to define a point that all threads need to reach before continuing the program execution
OpenMP master construct allow us to define regions of the code that should only be executed by the master thread
Setting number of threads
Overview
Teaching: 10 min
Exercises: 5 minQuestions
How to control the number of threads created by OpenMP?
Objectives
Learn to control the number of OpenMP number threads by environment variable and programmatically
Setting the number of threads
In our previous “Hello World” example we noticed that OpenMP created 40 threads. This is because, if not specified, the parallel construct will create as many threads as there are processing units on your computer (i.e. 40 if running in compute on Hawk).
This behaviour can be modified globally by environment variable from a job script:
export OMP_NUM_THREADS=8
…or dynamically from within your code:
If using Fortran:
!$OMP PARALLEL NUM_THREADS(4)
or the default value using the function
omp_set_num_threads(4)
If using C,C++:
#pragma omp parallel private(tnum) num_threads(4)
or the default value using the function
omp_set_num_threads(4)
In this example we will create a simple OpenMP program that does the following:
- Creates a first parallel region with a defined number of threads
- Each thread in the first parallel region obtains and prints its unique thread number
- Creates a second parallel region without specifying the number of threads
- Each thread in the second parallel region obtains and prints its unique thread number
- Only the master will print the total number of threads
// Load the OpenMP functions library
#include<omp.h>
int main()
{
// Set variables
int tnum=0;
// Create a parallel block of four threads (including master thread)
/* #pragma omp parallel private(tnum) num_threads(4) */
/* { */
tnum = omp_get_thread_num();
printf("I am thread number: %d\n", tnum);
/* } */
// Create a parallel block, without specifying the number of threads
/* #pragma omp parallel private(tnum) */
/* { */
tnum = omp_get_thread_num();
printf("Second block, I am thread number %d\n", tnum);
/* } */
return 0;
}
Controlling the number of threads.
Let us begin by confirming that our code behaves in serial mode in the way we expect. For this you don’t need to make any modifications since the OpenMP directives are commented out at the moment. Go ahead and compile the code:
~/openmp/Intro_to_OpenMP.2019/c$ icc -qopenmp -o setthreads setthreads.cOnce we are satisfied with the serial version of the code, uncomment the OpenMP directives. Compile and run again. How does it behave? Try modifying the number of threads given to num_threads.
Using environment variables
This time try using the environment variable OMP_NUM_THREADS to control the number of threads that OpenMP creates by default. To do this, type in your command line:
~$ export OMP_NUM_THREADS=8And run the program again (notice that no compilation is needed this time). What happens?
Key Points
We can use the environment variable OMP_NUM_THREADS to control how many threads are created by OpenMP by default
OpenMP function num_threads have a similar effect and can be used within your code
Data sharing
Overview
Teaching: 15 min
Exercises: 5 minQuestions
How to divide a code in sections and assign each section to one thread?
Another way of assigning only one thread to a programs’ region
Objectives
Learn to use OpenMP sections and single constructs to better control how work is divided among threads
Understand the effect of implicit barriers and how to remove them
Other loop constructs
This time we have a code that have two well defined tasks to perform: 1) print a thread number 2) print a thread number, the total number of threads available, and the sum of all thread IDs.
In serial mode these tasks will be performed by the only thread available (0). But in parallel we can assign them to one thread each.
We will modify our example to add OpenMP directives that allow us to:
- Create a parallel region to be distributed among available threads
- Create a sections block to distribute available blocks to single threads
- Blocks are identified with a section directive
// Load the OpenMP functions library
#include<omp.h>
int main()
{
// Set variables
int num_threads=0, tnum=0, i=0, total=0;
// Create parallel block
//#pragma omp parallel
// {
//Create a section block
//#pragma omp sections private(tnum, i) nowait
// {
// Ask an available thread to print out the thread number.
//#pragma omp section
// {
tnum = omp_get_thread_num();
printf("I am thread number %d\n", tnum);
// }
// Ask another section to add up the thread numbers
//#pragma omp section
// {
num_threads = omp_get_num_threads();
tnum = omp_get_thread_num();
total = 0;
for (i=1; i<=num_threads; i++)
total = total + i;
printf("thread number %d says total = %d\n", tnum, total);
// }
// Close the section block. Normally this sets a barrier that requires all
// the threads to have completed processing by this point, but we've
// bypassed it with the "nowait" argument.
// }
// Print out the fact that the section block has finished. How many threads
// are still functional at this point?
printf("Finished sections block\n");
// We only want one thread to operate here.
//#pragma omp single
// {
tnum = omp_get_thread_num();
printf("Single thread = %d\n", tnum);
// }
// End parallel block
// }
return 0;
}
Creating sections
Let us begin by confirming that our code behaves in serial mode in the way we expect. For this you don’t need to make any modifications since the OpenMP directives are commented out at the moment. Go ahead and compile the code:
~/openmp/Intro_to_OpenMP.2019/c$ icc -qopenmp -o constructs constructs.cOnce we are satisfied with the serial version of the code, uncomment the OpenMP directives that create the parallel and sections regions. Recompile and run again. How does it behave?
Single thread
The output of our program looks a bit lengthy due to all threads reaching the last printing command. If we wanted this section to be executed by only one thread we could try using OpenMP directive single. Go ahead and uncomment this directive. Recompile and run the program. What is the output this time?
Implicit barriers
Our sections OpenMP directive by default creates an implicit barrier at the end of its defined region. In our example we removed it with a nowait clause that caused threads to continue executing the program without waiting for all other threads to finish the sections region. Several constructs have this behaviour (e.g. parallel, single)
#pragma omp sections private(tnum, i) nowaitTry removing the nowait clause. Recompile and run the program. How it behaves this time? Can you see the effect of the implicit barrier?
Sections
The sections construct is a non-iterative worksharing construct that contains a set of structured blocks that are to be distributed among and executed by the threads in a team. Each structured block is executed once by one of the threads in the team in the context of its implicit task.
Single
The single construct specifies that the associated structured block is executed by only one of the threads in the team (not necessarily the master thread), in the context of its implicit task. The other threads in the team, which do not execute the block, wait at an implicit barrier at the end of the single construct unless a nowait clause is specified.
OpenMP parallelization strategy
- Start with a correct serial execution of the application
- Apply OpenMP directives to time-consuming do loops one at a time and TEST
- Keep private variables and race conditions always in mind
- Use a profiler or debugger in case of strange results or crashes
- Results should be bit reproducible for different numbers of threads
- Avoid reductions for reals (except: max, min)
- Fortran array syntax supported with WORKSHARE
Race conditions
Consider the following example. Where we are looking at estimating a best cost through a computationally expensive function (a random function for the sake of demonstration). We perform a for loop in which we compare with previous obtained costs and if a new minimum is found, the best cost is updated. At the end we print the overall best cost.
#include<omp.h>
#include<stdlib.h>
int main()
{
srand (time(NULL));
int i;
int N=20;
int best_cost=RAND_MAX;
#pragma omp parallel shared(best_cost)
{
#pragma omp for nowait
for (i=0; i<N; i++)
{
int tid = omp_get_thread_num();
int my_cost;
// Be careful using rand inside parallel region.
// Some rand implementations may not be thread safe.
my_cost = rand() % 100;
printf("tid %i - %i\n",tid,my_cost);
//#pragma omp critical
if(best_cost > my_cost)
{
printf("tid %i says that %i is lower than %i \n",tid,my_cost,best_cost);
best_cost = my_cost;
}
}
}
printf("Best cost %d\n",best_cost);
}
Debugging race conditions
Try running in serial mode (compile without -qopenmp flag) the example above and analize the ouput.
~/openmp/Intro_to_OpenMP.2019/c$ icc -o race race.cDoes it work as expected? Try this time adding openmp support to parallelize the for loop:
~/openmp/Intro_to_OpenMP.2019/c$ icc -qopenmo -o race race.cWhat do you notice?
Critical
When ensuring that shared date is accessed only by one thread at a time, you can use the critical construct. Try adding the following directive immediately before our if statement:
#pragma omp critical
{
...
}
Compile and run the program again. Does the output changes?
Key Points
The OpenMP sections construct allow us to divide a code in regions to be executed by individual threads
The OpenMP single construct specifies that a code region should only be executed by one thread
Many OpenMP constructs apply an implicit barrier at the end of its defined region. This can be overruled with nowait clause. However, this should be done carefully as to avoid data conflicts and race conditions
Synchronization
Overview
Teaching: 10 min
Exercises: 5 minQuestions
How to use OpenMP synchronization directives
Objectives
Use master, barrier and critical constructs to better control our threads are synchronized
Synchronization
As we have seen previously, sometimes we need to force a thread to ‘lock-out’ other threads for a period of time when operating on shared variables, or wait until other threads have caught up to ensure that a calculation has been completed before continuing. OpenMP directives useful for this purpose are:
- MASTER Only the master thread will execute this code
- SINGLE Only one thread will execute this code
- CRITICAL Threads must execute code one at a time
- BARRIER Waits until all threads reach this point
Let us take a look at the following example. In this case, the serial version of this code simply increments a counter by 1, prints the thread ID number, waits for 10 seconds and confirms that the program finished.
We might want to rewrite this code to work in parallel. Perhaps our counter is keeping track of how many threads have finished successfully, or perhaps it represents a line in a text file where every entry is the name of a data file that needs to be processed. In any case, we might want to ensure that it is updated carefully.
Example (serial)
// Load the OpenMP functions library #include<omp.h> int main() { // Set and initialise variables int tnum=0, incr=0; // Start a critical block that we want only one thread to access // at a time. Note that the 'incr' variable is NOT private! incr = incr + 1; // The master thread prints out the results of the calculation and // then does some other processing that the other threads have to // wait for. tnum = omp_get_thread_num(); printf("Master thread is number %d\n", tnum); printf("Summation = %d\n", incr); sleep (10); // Ensure ALL threads have finished their processing before continuing. printf("finished!\n"); return 0; }
Example (parallel)
// Load the OpenMP functions library #include<omp.h> int main() { // Set and initialise variables int tnum=0, incr=0; // Start parallel block #pragma omp parallel private(tnum) { // Start a critical block that we want only one thread to access // at a time. Note that the 'incr' variable is NOT private! #pragma omp critical { incr = incr + 1; } #pragma omp barrier // The master thread prints out the results of the calculation and // then does some other processing that the other threads have to // wait for. #pragma omp master { tnum = omp_get_thread_num(); printf("Master thread is number %d\n", tnum); printf("Summation = %d\n", incr); sleep (10); } // Ensure ALL threads have finished their processing before continuing. #pragma omp barrier { printf("finished!\n"); } } return 0; }
More race conditions
Let us begin by confirming that our code behaves in serial mode in the way we expect. For this you don’t need to make any modifications since the OpenMP directives are commented out at the moment. Go ahead and compile the code:
~/openmp/Intro_to_OpenMP.2019/c$ icc -qopenmp -o sync sync.cOnce we are satisfied with the serial version of the code, uncomment the OpenMP directives that create the parallel region. Recompile and run again. How does it behave? How can it be improved?
Key Points
OpenMP constructs master, barrier and critical are useful to define sections and points in our code where threads should synchronize with each other
Reduction operation
Overview
Teaching: 15 min
Exercises: 5 minQuestions
How to use OpenMP reduction directives
Objectives
Use copyprivate and reduction constructs to communicate data among threads
Broadcast and reduction
At the end of a parallel block performing some computation, it is often useful to consolidate the result held by a private variable in each thread into single value, often performing some operation on it in the process.
- copyprivate Broadcast a single value to a private variable in each thread
- reduction Perform an operation on each threaded private variable and store the result in a global shared variable.
Let us take consider the following example. The serial version of this code simply obtains and prints a value to broadcast (in this case its thread ID number) and then performs a calculation of 2 elevated to the power given by its thread ID number and prints the result.
In parallel, the aim is to keep the section of the code where only one thread obtains the broadcast value, but then communicates it to the other threads in the team. And then, have each thread perform the calculation using its own ID number. At the end of the program we want to print the sum of the individual values calculated by each thread.
Example (serial)
// Load the OpenMP functions library #include<omp.h> #include<math.h> //for pow function int main() { // Set and initialise variables int broad=0, tnum=0, calc=0; broad = omp_get_thread_num(); // Print out the broadcast value printf("broad = %d\n", broad); calc = 0; tnum = omp_get_thread_num(); calc = pow(2,tnum); printf("Thread number = %d calc = %d\n",tnum, calc); printf("Reduction = %d\n", calc); return 0; }
Example (parallel)
#include<omp.h> #include<math.h> //for pow function int main() { // Set and initialise variables int broad=0, tnum=0, calc=0; // Start parallel block #pragma omp parallel private(broad,tnum,calc) { // We want a single thread to broadcast a value to the entire block of // threads. #pragma omp single copyprivate(broad) { broad = omp_get_thread_num(); } // Print out the broadcast value printf("broad = %d\n", broad); } calc = 0; // Each thread in this block will perform a calculation based on its thread // number. These results are then reduced by performing an action on them, in // this case a summation. #pragma omp parallel private(tnum) reduction(+:calc) { tnum = omp_get_thread_num(); calc = pow(2,tnum); printf("Thread number = %d calc = %d\n",tnum, calc); } printf("Reduction = %d\n", calc); return 0; }
Using broadcast and reduction constructs
Let us begin by confirming that our code behaves in serial mode in the way we expect. For this you don’t need to make any modifications since the OpenMP directives are commented out at the moment. Go ahead and compile the code:
~/openmp/Intro_to_OpenMP.2019/c$ icc -qopenmp -o reduc reduc.cOnce we are satisfied with the serial version of the code, uncomment the OpenMP directives that create the parallel region. Use broadcast and reduction to achieve the objectives of this exercise. Did you run into any issues?
Other reduction constructs
C,C++
-
Operators +, -, *, &&, , - Intrinsics max, min
Fortran
- Operators +, -, *, .AND., .OR., .EQV., .NEQV.
- Intrinsics MAX, MIN, IAND, IOR, IEOR
Key Points
OpenMP constructs copyprivate and reduction are useful to pass values obtained by a one or more threads to other threads in the team, and to perform some recurrence calculations in parallel
OpenMP and Slurm
Overview
Teaching: 15 min
Exercises: 5 minQuestions
Some pointers on how to run OpenMP on Slurm
Objectives
Some considerations when submitting OpenMP jobs to Slurm
Using OpenMP and Slurm together
Slurm can handle setting up OpenMP environment for you, but you still need to do some work.
....
#SBATCH –-cpus-per-task=2
...
# Slurm variable SLURM_CPUS_PER_TASK is set to the value
# of --cpus-per-task, but only if explicitly set
# Set OMP_NUM_THREADS to the same value as --cpus-per-task
# with a fallback option in case it isn't set.
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-1}
... run your OpenMP program ...
Make sure you specify tasks as 1 if only using OpenMP. If using MPI and OpenMP you have to be careful to specify –ntasks-per-node and –cpus-per-task to not exceed the number of cores on the node.
....
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=4
#SBATCH –-cpus-per-task=2
...
# Slurm variable SLURM_CPUS_PER_TASK is set to the value
# of --cpus-per-task, but only if explicitly set
# Set OMP_NUM_THREADS to the same value as --cpus-per-task
# with a fallback option in case it isn't set.
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK:-1}
... run your MPI/OpenMP program ...
High-level control
Slurm has options to control how CPUs are allocated. See the man pages or try the following for sbatch.
--sockets-per-node=S : Number of sockets in a node to dedicate to a job (minimum)
--cores-per-socket=C : Number of cores in a socket to dedicate to a job (minimum)
--threads-per-core=T : Number of threads in a core to dedicate to a job (minimum)
-B S[:C[:T]] : Combined shortcut option for --sockets-per-node, --cores-per_cpu, --threads-per_core
Further training material
Key Points
Use Slurm –cpus-per-task option to request the number of threads
Set OMP_NUM_THREADS equal to the number of cpus per task requested
Be careful not to exceed the number of cores available per node
Advanced features
Overview
Teaching: 10 min
Exercises: 5 minQuestions
Some pointers on further OpenMP features
Objectives
Understand further material and topics that can used.
Using OpenMP on GPUs
GPUs are very efficient at parallel workloads where data can be offloaded to the device and processed since communication between GPU and main memory is limited by the interface (e.g. PCI).
NVIDIA GPUs are available and usually programmed using NVIDIA’s own CUDA technology. This leads to code that is limited
to only working on NVIDIA’s ecosystem. This limits choice for the programmer and portability for others to use your
code. Recent versions of OpenMP since 4.0 has supproted offload functionality.
Info from Nvidia suggests this is possible but still work in progress. Compilers have to be built to support CUDA (LLVM/Clang is one such compiler).
Example code is:
#pragma omp \
#ifdef GPU
target teams distribute \
#endif
parallel for reduction(max:error) \
#ifdef GPU
collapse(2) schedule(static,1)
#endif
for( int j = 1; j < n-1; j++)
{
for( int i= 1; i < m-1; i++ )
{
Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1]+ A[j-1][i] + A[j+1][i]);
error = fmax( error, fabs(Anew[j][i] -A[j][i]));
}
}
If interested, come and talk to us and we can see how we can help.
Further material
- https://www.openmp.org
Key Points
OpenMP is still an evolving interface to parallel code.